1 概览
JVM是一种技术规范,不同的厂商可能会有些不同的定义,根据规范,普遍被接受的一种架构如下。
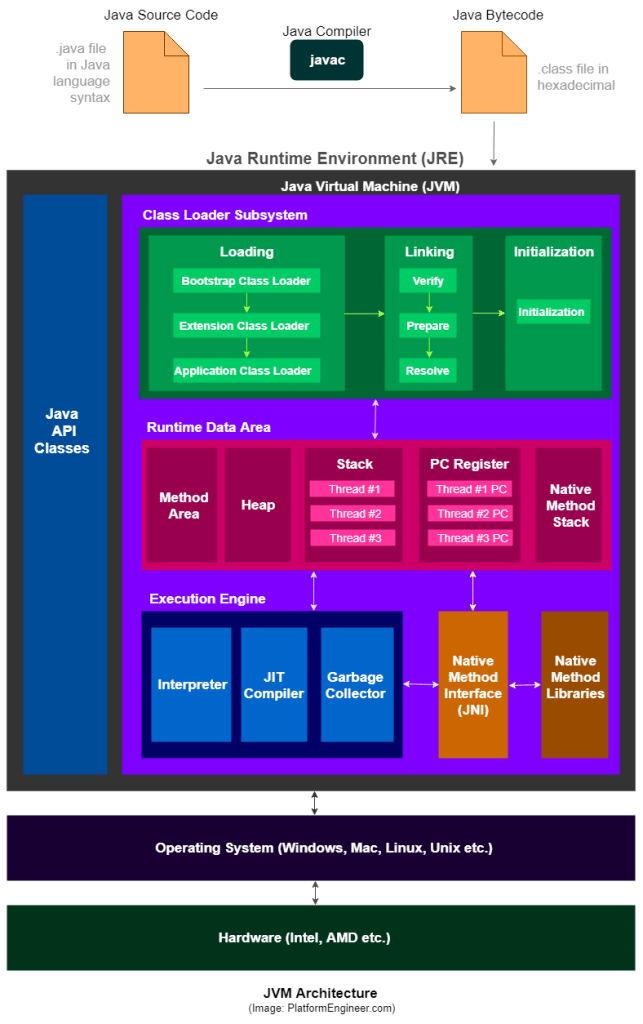
2 类加载器子系统(Class loader subsystem)
JVM处于RAM中,在执行过程中,使用类加载器子系统将类文件引入RAM,这叫类动态加载功能,在运行时(非编译时)第一次引用一个类的时候会进行加载、连接、初始化相应的类文件(.class)。
2.1 加载(Loading)
载入编译过的类文件(.class文件)到内存中是类加载器的主要任务,所有之后的类载入会根据已经运行的类中的引用进行,相关的场景如下
1) 当字节码对一个类做了静态引用 (例如System.out)
2) 当字节码创建了一个类对象 (例如 Person person = new Person(“John”))
有三种类加载器(具有继承关系),它们遵循以下四个主要原则:
1 | - 可见原则(visibility principle) |
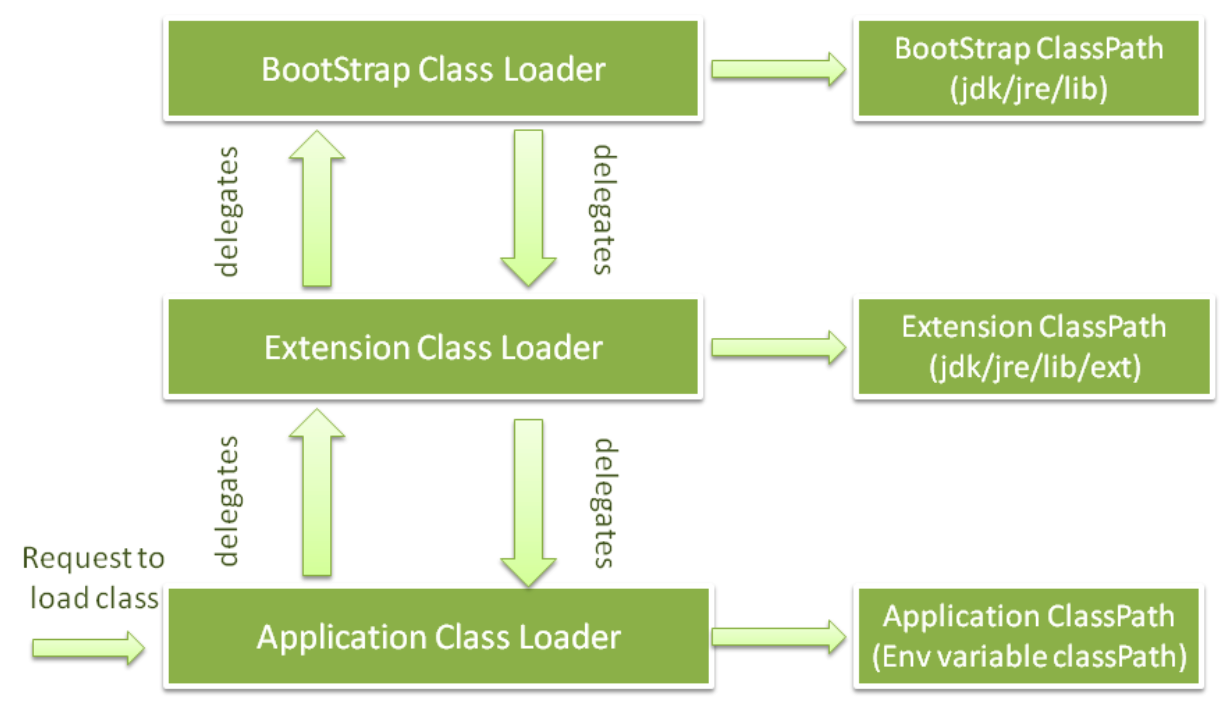
上图描述了三个类加载器以及类加载器的双亲委派机制,各加载器的描述如下
TODO: class loader启动过程
Bootstrap Class Loader
Bootstrap Class Loader从bootstrap路径($JAVA_HOME/jre/lib)中的rt.jar中载入标准JDK类,比如核心的Java API类(例如 java.lang.* package classes),它是用Native语言(如C/C++)来实现的,在java中表现为所有类加载器的双亲(顶层类加载器)。Extension Class Loader
Extension Class Loader委派类加载请求给它的双亲Bootstrap Class Loader,如果不成功,会从extentsion路径的extension路径($JAVA_HOME/jre/lib/ext或是java.ext.dirs系统属性置顶的路径)载入类(例如 security extension function),这个类加载器在Java中通过sun.misc.Launcher$ExtclassLoader类实现。System/Application Class Loader
System/Application Class Loader从系统类路径中加载应用指定的类,当启动应用程序的时候可以使用-cp或-classpath命令行选项来设置该路径。这个内部是使用匹配到java.class.path的环境变量。这个类加载器在Java中通过sun.misc.Launcher$AppClassLoader类实现。
注意:除了上述的三种主要的类加载器,程序员可以自定义类加载器。通过类加载器的委派模型保证了应用的独立性。这种方法被用在web应用服务器,如Tomcat,使得web应用和企业解决方案独立运行。
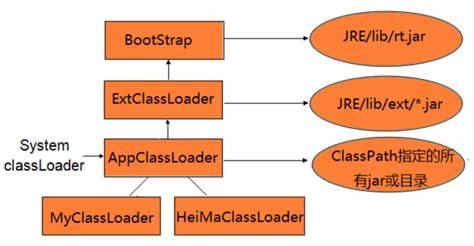
每个类加载器有自己命名空间来存储载入的类。当一个类加载器加载一个类,会基于存储在命名空间中的FQCN(Fully Qualified Class Name)来确认类是否已经加载了类。即使类有相同的FQDN,但是命名空间不同,也被认为是不同的类。不同的命名空间意味着类被另一个加载器载入过。
2.2 链接(Linking)
链接过程包括验证和准备载入的类和接口,它的超类和超接口,还有必要时它的元素类型
- 类和接口必须在链接之前完全载入
- 类和接口在初始化之前必须完全验证和准备
- 如果在链接过程中发生错误,它抛在程序中的某个点,在该点程序会执行一些操作,直接或间接的要求链接到错误中涉及的类或接口。链接发生在以下三个阶段:
验证(verification)
确保.class文件的正确性(代码是否准确的根据Java语言规范编写,是否通过符合JVM规范的有效编译器生成?)。这是类加载处理过程中最复杂的测试过程,并且花最长的时间。即使链接减慢了类的加载过程,但是它避免了执行字节码的时候执行多次检查,因此使得整体执行更加有效和有效率。如果验证失败,会抛错误(java.lang.VerifyError)。例如,下列的检查会被执行。
○ 一致和正确格式化的符号列表 ○ final方法/类没有override ○ 方法遵循访问权限控制关键字 ○ 方法具有正确的参数数量和类型 ○ 字节码不能正确填装栈 ○ 变量在被读取前进行了初始化 ○ 变量是正确类型的值准备(preparation)
为JVM使用的静态存储和任何数据结构分配内存比如方法表。静态字段被创建并初始化为默认值,不过这个阶段不会执行初始化程序或代码,因为这个事发生在 初始化阶段。解析(resolution)
使用直接引用替换类型的符号引用,这是通过搜索方法区来定位被引用的实体。
2.3 初始化(Initialization)
在这个阶段,每个加载的类或接口的初始化逻辑会被执行(比如类的构造函数的调用)。因为JVM是多线程,类或接口的初始化应该小心的使用适当的同步来避免一些其他线程同时尝试初始化同样的类或接口。(使得线程安全)
这是类加载的最后阶段,在这个阶段所有静态变量会分配代码中定义的原始值,并且如果有静态代码块的话会被执行。这个会从顶部到底部逐行执行并且从父类到自类的顺序执行。
3 运行时数据区域(Runtime Data Area)
运行时数据区域是JVM程序在操作系统上运行时分配的内存区域,除了读取.class文件之外,类加载器子系统生成相应的二进制数据并且分别为每个类保存如下的信息到方法区中。
- 载入类和它的直接父类的完全限定名称
- 是否.class文件跟Class/Interface/Enum有关
- 修饰符,静态变量和方法信息等
对于每个载入的.class类,它创建类的一个对象来表示堆内存中的文件,就像java.lang包中定义的。这个类对象之后在代码中能用来读取类层次的信息(类名称,父类名称, 方法,变量信息,静态变量等等)。
3.1 方法区(Method Area,线程间共享)
这个是共享资源(每个JVM只有一个方法区)。所有的JVM线程共享方法区,所以访问方法数据和动态链接处理一定是线程安全的。
方法区存储类层次的数据(包含静态变量)比如:
- 加载器引用
- 运行时静态量池 - 数字常量,字段引用,方法引用,属性;每个方法和接口的常量也一样,它包含了方法跟字段的所有引用。当一个方法或字段被引用,JVM运用运行时常量池在内存中搜索方法或字段的实际地址。
- 字段数据 - 每个字段: 名字,类型,修饰符,属性
- 方法数据 - 每个方法: 名字, 返回类型,参数类型(按顺序),修饰符,属性
- 方法代码 - 每个方法:字节码,运算符栈大小,本地变量大小,本地变量表,异常表;在异常表中每个异常处理程序:开始点,结束点,处理程序代码的PC偏移量,捕捉的异常类的常量池索引
3.2 堆区域(Heap Area,线程共享)
这个也是共享资源(每个JVM只有一个堆区域)。所有对象的信息和它们对应的实例变量和数组被存储在堆区域。因为方法区和数据区对于多线程是共享内存,存储在方法区和堆区的数据不是线程安全的。堆区是GC的一个大目标。
3.3 栈区域(Stack Area,线程独享)
这个不是共享资源。对于每个JVM线程,当线程开始的时候,一个单独的运行时栈被创建用来存储方法调用。对于每个这样的方法调用。一个实体将被创建并且加入(推入)运行时栈顶,这样的实体被叫做栈帧。
每个栈帧都有对本地变量数组的引用,操作数栈,和正在执行类的运行时常量池。本地变量的尺寸和操作数尺寸是在编译中决定的。因此,栈帧的尺寸根据方法是固定的。
当方法正常返回或是方法调用过程中抛出未捕获的异常的时候帧会被移除(弹出)。注意如果任何异常发生, stack trace(可以通过方法显示,如printStackTrace())的每一行表达了一个栈帧。因为栈区域不是共享资源所以栈区域是线程安全的。
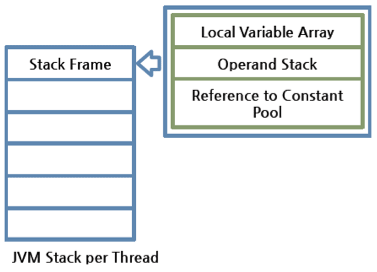
栈帧被分为三个子实体
- 本地变量数组(Local Variable Array)
有从0开始的索引。对于一个特定的方法,有多少个被涉及的变量以及相应的值被存储在这里。索引0是方法所属的类的引用,从1开始,存储传给方法的参数,在方法参数之后,存储方法的本地参数。 - 操作数栈(Operand Stack)
如果有需要这里表现为运行时工作空间来执行任何立时操作。每个方法在操作数栈和本地变量数组之间交换数据,并压入或弹出其他方法调用结果。操作数栈空间的必要大小可以在编译期间决定。因此,操作数栈的大小也能够在编译期间决定。 - 帧数据(Frame Data)
所有跟方法相关的符号存储在这里。对于异常,捕捉块信息也将在帧数据中维护。
因为有运行时栈帧,在一个线程终止之后,它的栈帧也将会被JVM销毁。
栈可以是动态的或固定的尺寸。如果线程请求太大的栈(比允许的更大)就会抛StackOverflowError。如果线程请求一个新的帧并且没有足够的内存来分配,OutOfMemoryError会被抛出。
3.4 PC计数器(PC Registers,线程独享)
对于每一个JVM线程,当线程启动,一个单独的PC(program counter)计数器被创建来持有当前正在执行指令的地址(在方法区中的内存地址)。如果当前方法是native的,PC是没有定义的。一旦执行结束,PC计数器会用下一个指令的地址进行更新。
3.5 Native方法栈(Native Method Stack,线程独享)
在Java线程和Native操作系统线程之间有直接的映射。在为一个Java线程准备所有的状态之后,一个单独的Native栈会被创建来存储通过JNI(Java Native Interface)调用的Native方法信息(通常是用C/C++编写)。
一旦Native线程被创建和初始化,它会调用Java线程中的run()方法。当run()方法返回,未捕获的异常(如果有的话)被处理,Native线程确认是否由于线程的终结JVM需要终结。(例如:是否这是最后一个非守护线程)。当线程终止,所有Native和Java线程的资源都会被释放。
一旦Java线程被释放Native线程会被回收。操作系统因此负责调度所有线程并且分发它们给任何任何有效的CPU。
4 执行引擎
字节码的实际执行发生在这里。执行引擎逐行读取分配给上述运行时数据区域的数据并执行字节码中的指令。
4.1 解释器(Interpreter)
解释器解释字节码并且一条一条的执行指令。因此,它能很快的解释一行字节码,但是执行被解释的结果是一项更慢的任务。缺点是当一个方法被调用多次,每一次调用要求一个新的解释和一个更慢的执行。
4.2 即时编译器(Just-In-Time(JIT)编译器)
如果只有解释器可用,当一个方法被调用多次,每一次调用解释也会发生,如果都被有效处理的话是冗余操作。使用JIT编译器的话,首先,编译器会将整个字节码编译为native代码(机器码)。然后对于多次方法调用,它会直接提供Native代码并且使用Native代码的执行方式比一行一行解释指令的方式要快。Native代码存储在cache,这样被编译的代码会被更快的执行。
尽管如此,即使是JIT编译器,编译比解释器的解释花更多的时间。对于只执行一次的代码段,最好使用解释来代替编译。Native代码也存在cache中,这个一种很贵的资源。由于这些状况,JIT编译器内部会检查每个方法调用的频率并且决定只有当选中的方法已经发生一定程度的次数才会进行编译。这种适应性编译的想法被用在Oracle Hotspot VM中。
当引入JVM供应商的性能优化方案时执行引擎有资格成为一个关键子系统,在这些努力中,下面四种部件能够很大提高性能。
- 中间代码生成器产生中间代码
- 代码优化器负责优化上面生成的中间代码
- 目标代码生成器负责生成Native代码(例如 机器码)
- 分析器是一个特殊部件,负责找到性能瓶颈 也称为hotspots (例如 方法被调用多次的实例)
下面这种架构图有对这四个部件进行粗略直观的描述。
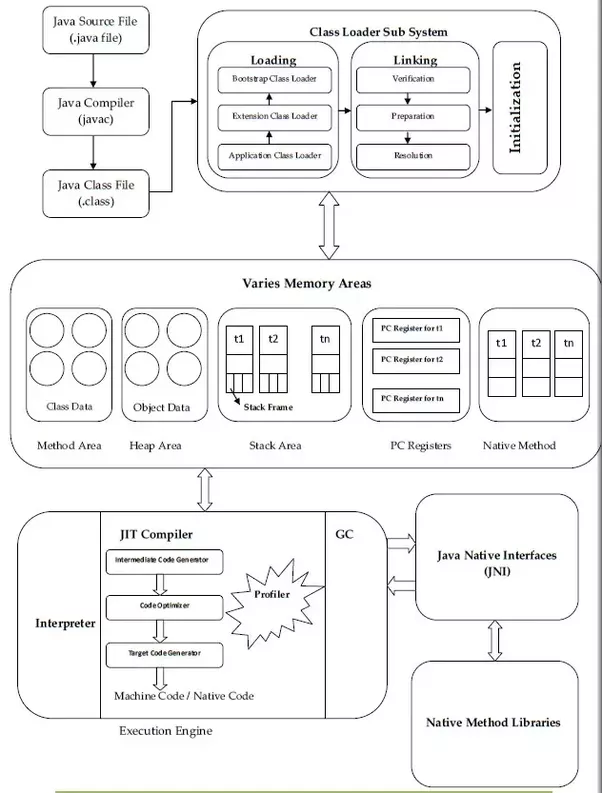
4.3 垃圾收集器(Garbage Collector, GC)
只要对象被引用,JVM认为它是活的。一旦对象不再被引用并且对于应用程序不可达,垃圾收集器会移除它并回收未被使用的内存。总的说,垃圾收集发生在后台,尽管如此我们能通过System.gc()方法触发它。(执行不能被保证,因此,调用Thread.sleep(1000) 并等待GC完成)
5 Java Native Interface(JNI)
这个接口被用来跟执行程序中要求的Native方法库进行交互,并且提供Native库的能力(常使用C/C++编写)。这个使JVM能够调用C/C++库并且能被特定于硬件的C/C++库调用
6 Native方法库
这是执行引擎必须的的C/C++ Native库的集合,能够通过Native接口访问。
7 JVM线程
我们讨论了Java程序如何运行,但是没有特别提及执行器。实际上为了执行之前提及的每个任务,JVM并发运行多线程。这些线程中的一些携带程序逻辑,并且被程序创建(应用线程),而其他的被JVM创建来执行系统后台任务(系统线程)。
主要的应用线程是主线程,它的创建是调用public static void main(String[])的部分,其他应用线程是由这个主线程创建的。应用线程执行任务,类似main()方法中开始的运行指令,如果在任何方法逻辑中发现new关键字在堆中创建对象等。
主要的系统线程如下:
- 编译器线程
在运行时,字节码编译成native代码由这些线程承担 - GC线程
所有GC相关的活动都由这些线程实施 - 周期性任务线程
调度周期性操作执行的定时器事件(比如 中断)被这个线程执行 - 信号分发线程
这个线程接受发给JVM进程的信号并且通过调用适当的JVM方法在JVM中处理它们 - VM线程
作为前提条件,一些操作需要JVM来达到一个安全点,在这里堆区域的修改不再发生。这个场景的例子有“stop-the-world”垃圾搜集,线程栈dumps,线程挂起和偏向锁撤销。这些操作在一个叫做VM线程的特殊线程上执行。
8 一些理解的关键点
Java被认为是解释语言和编译语言
通过设计,由于动态链接和运行时解释Java很慢
JIT编译器通过用native代码替换字节码来弥补解释器重复操作的缺点
最新版本的Java版本针对原始架构中的瓶颈
JVM只是一个技术规范,供应商在实现过程中可以自由自定义,创新和改进性能
参考材料
1. https://medium.com/platform-engineer/understanding-jvm-architecture-22c0ddf09722
2. https://medium.com/platform-engineer/understanding-java-memory-model-1d0863f6d973
3. https://codepumpkin.com/typesof-class-loader/
4. https://www.quora.com/In-which-different-parts-of-the-Java-Virtual-Machine-does-the-class-loader-load-the-classes

